WHAT WE DO
Data Engineering Manifesto
The manifesto is a set of principles that will make sure your projects will be delivered on time, empower your people, and ensure the stability of your products.
This is based on our collective experience from all of our projects.
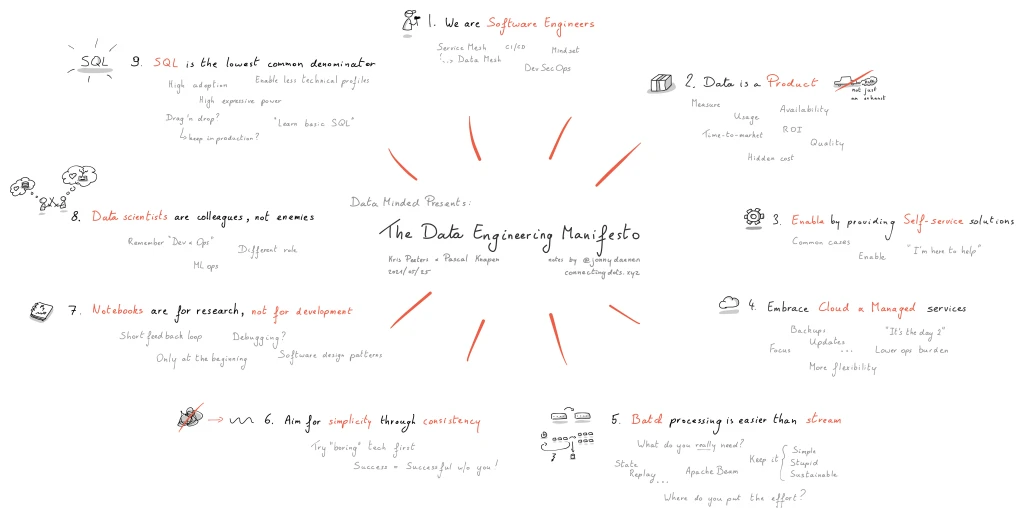
1. We are software engineers.
A data engineer creates software by writing code while following best practices. This includes adopting software design principles, version control, automated testing, CI/CD, Cloud-Native, and DevSecOps practices.
3. We enable by providing self-service solutions.
As data engineers, we build custom data pipelines for complex use cases. For more common use cases we provide self-service solutions. We are an enabler in an organisation.
5. Batch processing is easier than stream processing.
While it might be more interesting to build a real-time data stream, it can add unneeded complexity (state, replay, ... ). If your use case only requires data once per day, keep it simple, keep it stupid, keep it sustainable! This doesn’t mean we shy away from stream processing when needed.
7. Notebooks are for research, not for development.
Notebooks bring value at the beginning of a data product when exploring data, looking for potential solutions and documenting along the way. The structure of notebooks does not incentivize good software design patterns though. So once you are done exploring, a proper IDE is the right tool for the job.
9. SQL is the lowest-common denominator.
Over the years we have seen the rise of domain-specific languages and drag-and-drop tools. Nothing has come close to the expressiveness and adoption of SQL. We see it as the bridge to enable less technical profiles and we favor it as the interface in self-service solutions.