Blog
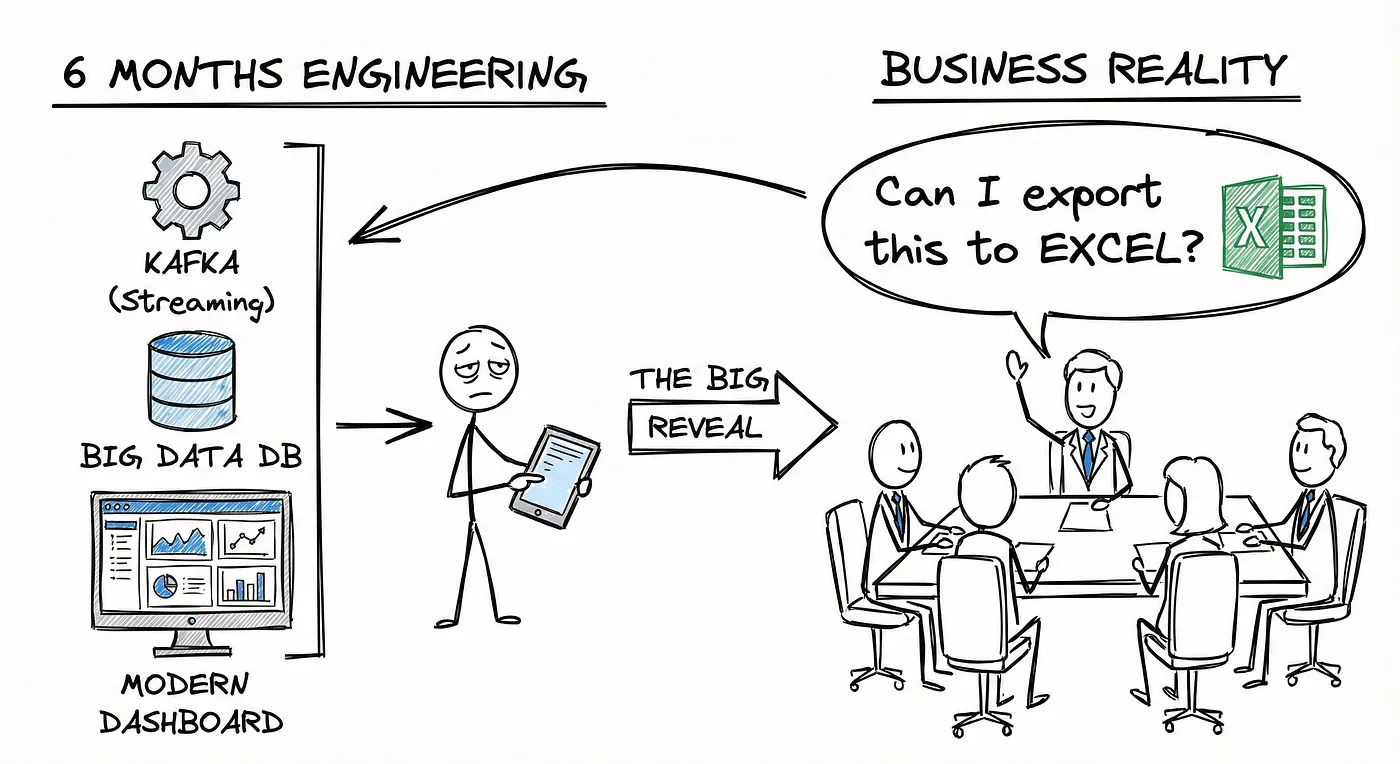
You Don’t Have a Data Platform Without Excel
The Most Used Feature is “Export”: Why Your Data Stack Needs a Spreadsheet Strategy

How Knowledge Graphs, Dimensional Models and Data Products come together
In a data-driven organisation data assets should be modelled in a way that allows key business questions to be answered.

Using AWS IAM with STS as an Identity Provider
How EKS tokens are created, and how we can use the same technique to use AWS IAM as an identity provider.

Slaying the Terraform Monostate Beast
You start out building your data platform. You choose Terraform because you want to do it the right way and put your infra in code.

How to Prevent Crippling Your Infrastructure When AWS US-EAST-1 Fails
Practical lessons on designing for resilience and how to reduce your exposure in case of a major cloud outage.
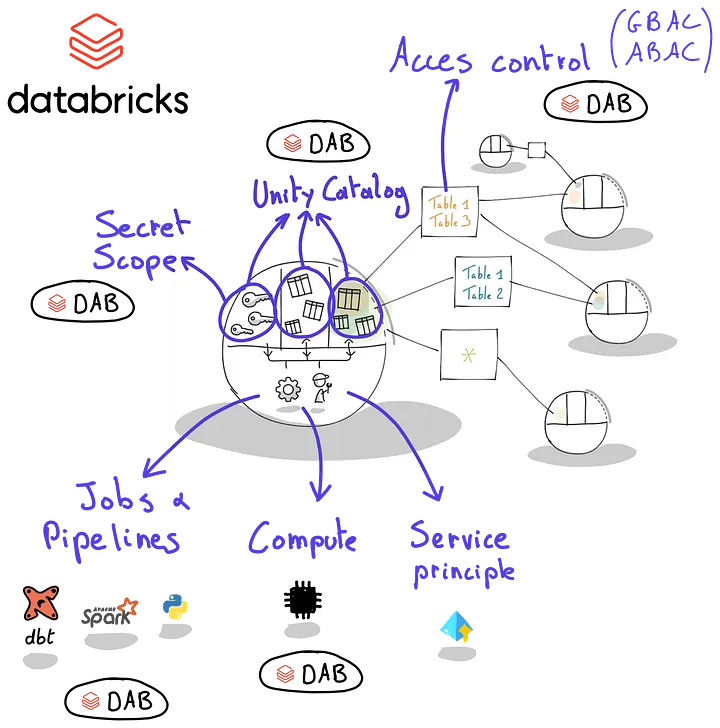
Setting up Databricks for data products
Building secure data products on Databricks is difficult due to its generic nature and the many concepts involved.
When writing SQL isn’t enough: debugging PostgreSQL in production
While writing efficient SQL queries is essential, it is not enough to operate a database at scale.

From Idea to Implementation: Building an MCP Server for The Data Product Portal
Adding an MCP to enable talking directly to your data using natural language.
Data Product Oriented Architectures
What is the state of the art in data products? Conclusions after the Second Summit on Data Product Oriented Architectures.

The ROI Challenge: Why Measuring Data’s Value is Hard, but Crucial
Too many data products, not enough ROI? Learn how to track value, cost & governance to manage data as a true business asset.

Authorizing AWS Principals on Azure
How to delegate trust from Entra to AWS IAM through Cognito, authorizing Azure actions without needing long-lived credentials.

Why Your Next Data Catalog Should Be a Marketplace
Why data catalogs fail - and how a Data Product Marketplace can rebuild trust, drive adoption, and unlock business value from your data.

Locking down your data: fine-grained data access on EU Clouds
Secure Iceberg data on EU clouds with fine-grained access for SQL, Python & Spark using Lakekeeper, Zitadel, and remote signing.

Rethinking the data product workbench in the age of AI
Rethinking how AI empowers data teams to build and maintain better data products without replacing them.

When writing SQL isn't enough: debugging PostgreSQL in production
SQL alone won’t fix broken data. Debugging pipelines requires context, lineage, and collaborationnot just queries.

Portable by design: Rethinking data platforms in the age of digital sovereignty
Build a portable, EU-compliant data platform and avoid vendor lock-in—discover our cloud-neutral stack in this deep-dive blog.

Cloud Independence: Testing a European Cloud Provider Against the Giants
Can a European cloud provider like Ionos replace AWS or Azure? We test it—and find surprising advantages in cost, control, and independence.

Stop loading bad quality data
Ingesting all data without quality checks leads to recurring issues. Prioritize data quality upfront to prevent downstream problems.

A 5-step approach to improve data platform experience
Boost data platform UX with a 5-step process:gather feedback, map user journeys, reduce friction, and continuously improve through iteration

What Is Data Product Thinking?
Data Product Thinking treats data as a product, empowering domain teams to own, improve, and scale trusted, user-focused data assets.

Why the ‘Private’ API Gateway of AWS Might Not Be as Secure as You Think
AWS Private API Gateways aren’t always private, misconfigs can expose access. Use resource policies to secure them properly.

The Data Engineer’s guide to optimizing Kubernetes
Boost Kubernetes batch workload efficiency with smarter scheduling, autoscaling tweaks & spot instance handling.

Integrating MegaLinter to Automate Linting Across Multiple Codebases. A Technical Description.
Automate code quality with MegaLinter, SQLFluff, and custom checks in Azure DevOps CI. Supports multi-language linting and dbt integration.

Are your AKS logging costs too high? Here’s how to reduce them
Cut Azure logging costs: reduce log volume, use Basic tables via the new ingestion API, and try a custom Fluentbit plugin with Go.

Source-Aligned Data Products: The Foundation of a Scalable Data Mesh
Source-Aligned Data Products ensure trusted, domain-owned data at the source—vital for scalable, governed Data Mesh success.

The State of Data Work in 2025: Insights From 32 In-Depth Conversations
Insights from 32 data professionals reveal 2025 challenges: balancing AI innovation, governance, quality, cost, collaboration, and literacy.

Monitoring thousands of Spark applications without losing your cool
Monitor Spark apps at scale with CPU efficiency to cut costs. Use Dataflint for insights and track potential monthly savings.

Data Modelling In A Data Product World
Central DWHs hit scaling limits. Data products offer a modular, federated solution—flexible, reusable, and closer to business reality.

SAP CDC with Azure Data Factory
Build SAP CDC in Azure Data Factory with SAP views, but high IR costs. Kafka + Confluent offers a cheaper, scalable alternative.

Beyond the Buzzwords: Let’s Talk About the Real Challenges in Data
Cut through data buzzwords join honest chats with data pros to uncover real challenges, knowledge gaps & clever wins.

From Good AI to Good Data Engineering. Or how Responsible AI interplays with High Data Quality
Responsible AI depends on high-quality data engineering to ensure ethical, fair, and transparent AI systems.

A glimpse into the life of a data leader
Data leaders face pressure to balance AI hype with data landscape organization. Here’s how they stay focused, pragmatic, and strategic.

Beyond Medallion: How to Structure Data for Self-Service Data Teams
Medallion architecture limits self-service. Shift to data product thinking with input, private, and output data for agile, governed scaling.

How we democratized data access with Streamlit and Microsoft-powered automation
Streamlit app + Power Automate = easy, self-serviced data access at scale, no YAML editing needed, just governance that actually works.

Unlocking the new Power of Advanced Analytics
Advanced analytics powered by LLMs and strong data engineering enables smarter predictions, deeper insights, and AI you can trust.

How To Conquer The Complexity Of The Modern Data Stack
The more people on a team, the more communication lines. Same goes for tools in your data stack, complexity scales fast

The Data Product Portal Integrates With Your Preferred Data Platform
Data Product Portal integrates with AWS to manage data products, access, and tooling—enabling scalable, self-service data platforms.

How To Reduce Pressure On Your Data Teams
Data demand grows, pressuring small teams. Shift to focused data product teams and use portals to stay efficient and avoid data siloes.

Microsoft Fabric’s Migration Hurdles: My Experience
Migrating to Microsoft Fabric?My experience shows it’s not ideal for modular platforms yet limited flexibility,IaC gaps & performance issues

Data Product Portal Integrations 2: Helm
Data Product Portal links governance, access & tools for self-service data on AWS. Supports Terraform & API integration for automation.

Data Stability with Python: How to Catch Even the Smallest Changes
Detect data changes efficiently by sorting and hashing DataFrames with Python—avoid re-running pipelines and reduce infrastructure costs.

Why You Should Build A User Interface To Your Data Platform
Don’t give users a bag of tools—build a UI for your data platform to reduce complexity, boost adoption, and enable true self-service.

Data Product Portal Integrations 1: OIDC
Integrate OIDC with the Data Product Portal for secure, user-specific access via SSO. Easy setup with AWS Cognito, Docker, or Helm.

The State of Data Products in 2024
Data Products are rising fast in 2024, focusing on user experience, collaboration, and governance—set to reach maturity within 2–3 years.

Clear signals: Enhancing communication within a data team
Clear team communication boosts data project success. Focus on root problems, structured discussions, and effective feedback to align better

Demystifying Device Flow
Implement OAuth 2.0 Device Flow with AWS Cognito & FastAPI to enable secure logins for headless devices like CLIs and smart TVs.

Introducing Data Product Portal: An open source tool for scaling your data products
The Data Product Portal is an open-source tool to build, manage & govern data products at scaleenabling clear access, lineage & self-service

Short feedback cycles on AWS Lambda
Speed up AWS Lambda dev with a Makefile: build, deploy, test, and stream logs in one loop boost feedback cycles to just ~15 seconds.

The Missing Piece to Data Democratization is More Actionable Than a Catalog
The Data Product Portal is the missing link for scaling data democratization, beyond catalogs, it unifies access, governance & tooling.

Prompt Engineering for a Better SQL Code Generation With LLMs Copy
Boost SQL generation with LLMs using prompt engineering, schema context, user feedback & RAG for accurate, business-aware queries.

Age of DataFrames 2: Polars Edition
In this publication, I showcase some Polars tricks and features.

Quack, Quack, Ka-Ching: Cut Costs by Querying Snowflake from DuckDB
How to leverage Snowflake’s support for interoperable open lakehouse technology — Iceberg — to save money.

The building blocks of successful Data Teams
5 key traits of successful data teams: ownership, business focus, software best practices, self-service, and company-wide strategy.

Querying Hierarchical Data with Postgres
Query hierarchical data in Postgres using recursive CTEs. Navigate up/down trees, track depth, and aggregate—great for parent-child data.

Securely use Snowflake from VS Code in the browser
Secure Snowflake SSO in browser-based VS Code using custom OAuth, CLI/API auth flow, and a dbt adapter for seamless cloud IDE integration.

The benefits of a data platform team
Build a dedicated data-platform team to manage ingest,storage & tools, freeing business data teams to focus on creating value from insights.

How to organize a data team to get the most value out of data
Data teams succeed by shifting from tech-only focus to value delivery—combine product thinking, business goals & cross-functional roles.

Why not to build your own data platform
A round-table discussion summary on imec’s approach to their data platform

Becoming Clout* certified
Hot takes about my experience with cloud certifications

You can use a supercomputer to send an email but should you?
Discover the next evolution in data processing with DuckDB and Polars

Two Lifecycle Policies Every S3 Bucket Should Have
Abandoned multipart uploads and expired delete markers: what are they, and why you must care about them thanks to bad AWS defaults.

How we used GenAI to make sense of the government
We built a RAG chatbot with AWS Bedrock and GPT4 to answer questions about the Flemish government.

My key takeaways after building a data engineering platform
Building a data platform taught me: deleting code is vital, poor design has long-term costs, and dependency updates are never-ending.

Leveraging Pydantic as a validation layer.
Ensuring clean and reliable input is crucial for building robust services.

7 Lessons Learned migrating dbt code from Snowflake to Trino
Snowflake to Trino dbt migration: watch out for type casting, SQL functions, NULL order, and window function quirks.

Growing your data program with a use-case-driven approach
Use-case-driven data programs balance planning & building, enabling fast value, reduced risk, and scalable transformation.

Everyone to the data dance floor: a story of trust
Data democratization is coming, but trust and governance are key. Start with pipeline observability: track runs, versions, and authors.

Quacking Queries in the Azure Cloud with DuckDB
DuckDB on Azure: fsspec works for now, but native Azure extension is faster—especially with many small files. Full support is on the way.

How we reduced our docker build times by 40%
This post describes two ways to speed up building your Docker images: caching build info remotely, using the link option when copying files

Cross-DAG Dependencies in Apache Airflow: A Comprehensive Guide
Exploring four methods to effectively manage and scale your data workflow dependencies with Apache Airflow.

Upserting Data using Spark and Iceberg
Use Spark and Iceberg’s MERGE INTO syntax to efficiently store daily, incremental snapshots of a mutable source table.
